Abstract
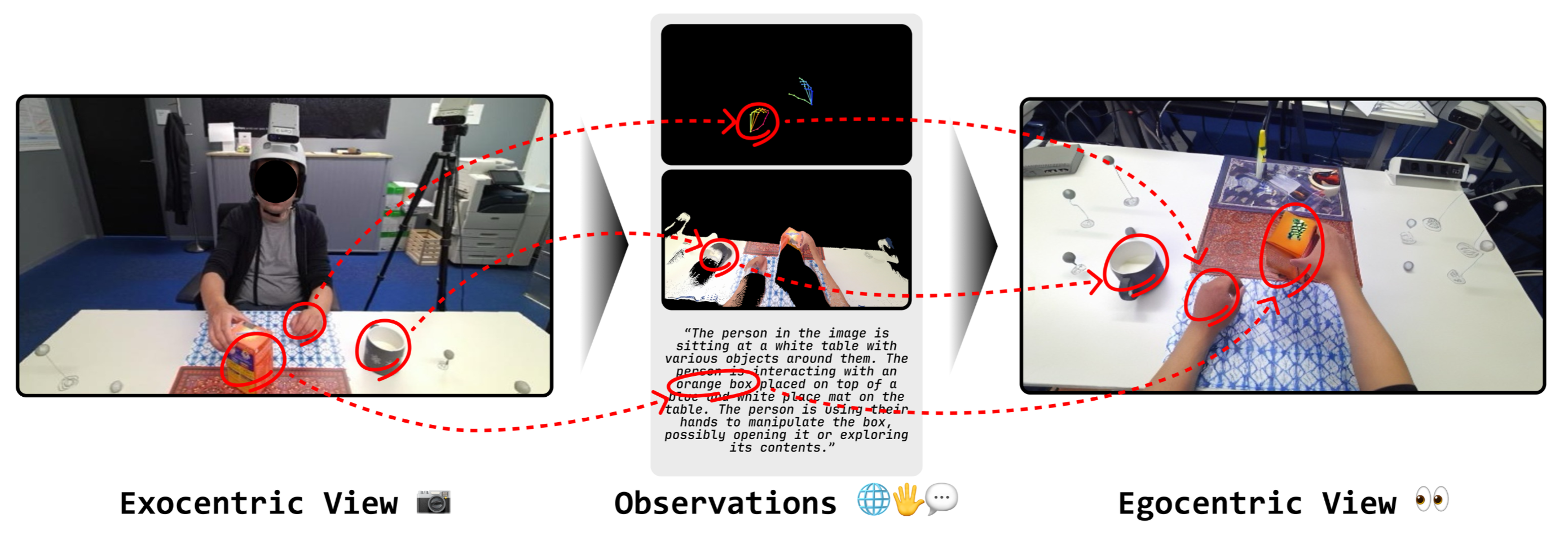
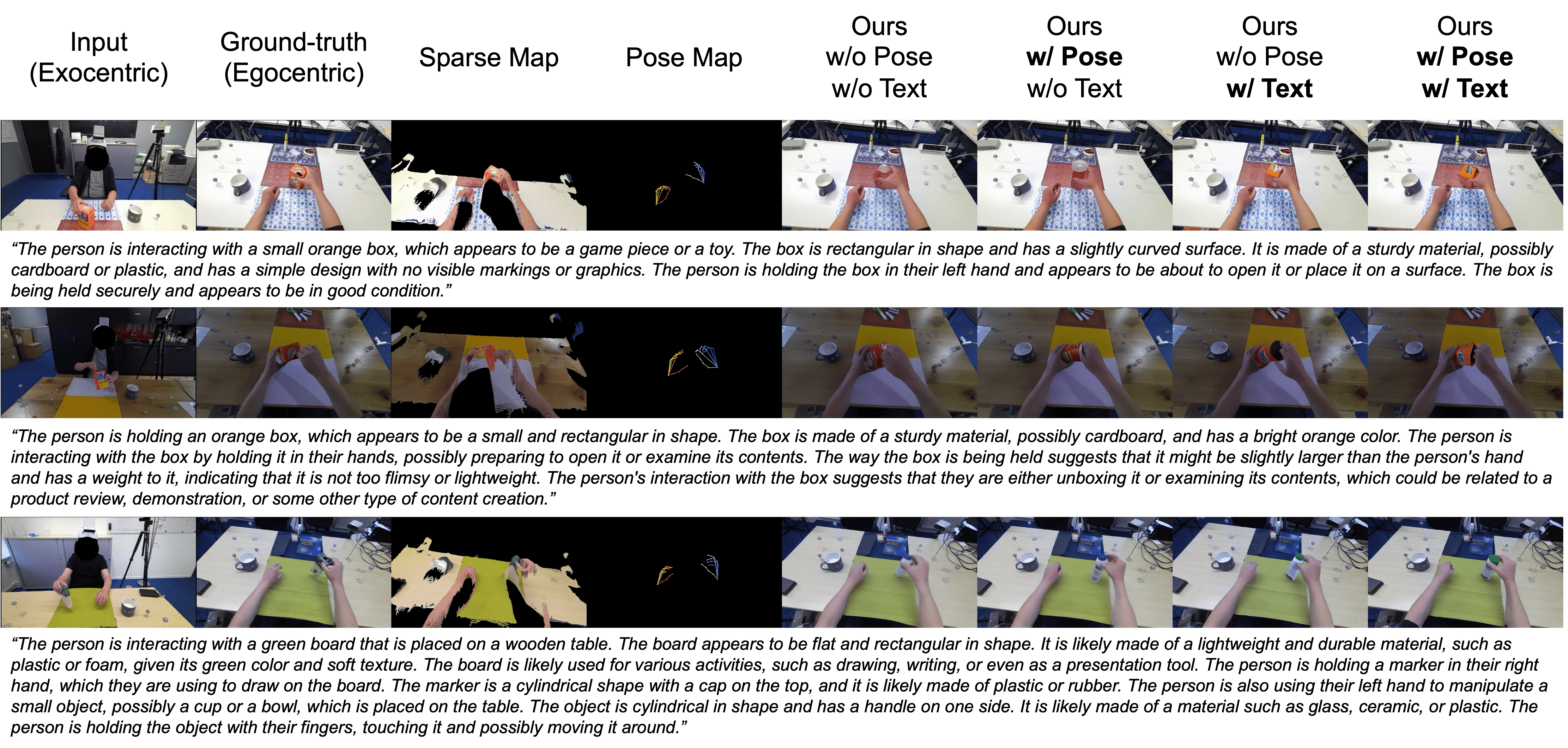
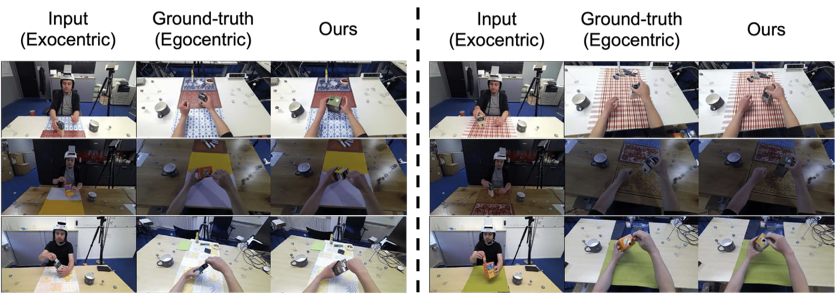
Egocentric vision is central to understanding fine-grained hand-object interaction, but translating an exocentric image into an egocentric view remains difficult when methods rely only on 2D cues, synchronized multi-view capture, or assumptions such as an initial egocentric frame and known relative camera poses at inference time. EgoWorld addresses that setting directly from a single exocentric image.
The framework first extracts rich exocentric observations, including an egocentric sparse RGB map derived from point clouds, an egocentric 3D hand pose, and a textual description of the scene and interaction. It then conditions a diffusion-based reconstruction model on those observations to generate dense, semantically coherent egocentric images. Across H2O, TACO, Assembly101, and Ego-Exo4D, EgoWorld achieves state-of-the-art performance and retains strong generalization on unseen objects, actions, scenes, subjects, and in-the-wild scenarios.